
Emotion Predictor and Facial Restoration
Project Description
Being able to predict and understand human emotions is important in many areas, such as education, games and movies. Especially in education it is crucial to detect when a learner is in a bad mood which can negatively influence the learning gain. Recently we have conducted a large user study where we have collected emotions as well as video recordings of users while they have been solving math tasks (active part) and looking at pictures (passive part). In this thesis we want to analyze this dataset to build predictive models of the user emotions based on video recordings (facial expression, eye gaze, head movement) and investigate if such a model can be generalized over different domains (pictures and math).
Tasks
The main task of the thesis is the development of a data-driven model for the prediction of the emotional state of a person based on the facial expression, eye gaze, head movement and distance to the screen. Moreover, it should be investigated if the built model generalizes over domains (from pictures to math and vice versa). Last but not least, an analysis of the best performing models should allow for insights into how to improve the prediction further. The four main tasks of this project are
- Validation and statistical analysis of the interaction log files and video data (e.g., correlation of self-reports with emotions retrieved from facial expressions)
- Timestamp synchronization, preprocessing and feature extraction from the video data.
- Creating predictive models for the user emotion while the user was solving math tasks and looking at pictures based on features extracted from the video data. Investigating the generalizability by applying the model built on math tasks to the task consisting of watching at pictures and vice versa.
- Preprocessing the tablet front cam data by stitching the two parts together (separated by the mirror) and incorporating the data into the model.
Result
Emotion Predictor
The participants have been recorded with two different video cameras, the front camera of the tablet and an external GoPro. Each participant was looking at 40 pictures and solved around 60 math tasks. After each image and math task, the participant rated the emotion with the two scales valence and arousal, each with a value between 1 (low) and 9 (high). In the beginning, we analyzed the log files about ratings, the delay in ratings, change of ratings, and the confidence of the extracted features. Then, we defined a valid timestamp synchronization between these two video sources and the underlying database. Some smaller adjustments for the videos have been made to ensure optimal facial recognition by the third party libraries (Affectiva and OpenFace). Based on these frameworks, we extracted the following facial features:
- Action Units
- Statistics on single action units
- Statistics on combined action units
- Eye Aspect Ratio (EAR) and blinks
- Mouth Aspect Ratio (MAR)
- Eye-Gaze features
- Movement
- On a single axis
- In the 3D space
- Statistics of the extracted fidgeting index
We normalized all features with the extracted features of a baseline video. To find the optimal baseline of a 7-minute video, we analyzed different statistics and performed various tests. Further analysis of the feature correlation has been made to ensure the correct behavior of some estimators.
We wrote a learning pipeline to extract the frames relative to a given point of interest. As for the pictures, we obtained the frames corresponding to the start when the image was shown, and for the math tasks, we extracted the frames relative to the end of the math task. Further, the duration could be specified to obtain only a defined number of frames. With this extraction, we first searched for the optimal shift (position relative to the event) and size (duration) of the frame. For the shift, we used values from -5 to 5 seconds, and for the duration, we used values between 0.5 and 10 seconds. The labels consisted of low (1-3) and high (7-9) valence and low (1-3) and high (7-9) arousal. Without further hyperparameter optimization, a trend became clear that essential frames are around the submitting of the current affective state for pictures as well for math tasks. On the one hand, we conclude that the highest impact on the facial expression is not the picture itself, but when the image is compared to the personal experience and memory to rate it. On the other hand, for math tasks, the highest impact is the success message, which informs the participant about the correctness of the given solution.
Once we found the optimal window, we ran a hyperparameter optimization with a random search on several parameters of the five most promising estimators. In the end, the performance was with an accuracy of around 0.8 for predicting the valence, whereas current solutions achieved only slightly above the random level. As the participants were involved more during the math tasks (the active part), the performance was also marginally better. The arousal performed slightly worse for the pictures (around 0.75) and a lot better for math tasks (0.9). The high performance for math tasks is probably because many participants rated only in one class over the whole experiment.
We detected a few possible problem sources during an analysis of the misclassified samples:
- Little Facial Expression
- Inconsistent Rating
- Misinterpretations
- Noise in Extracted Features
To verify the extracted features and the approach, we applied the same pipeline to the RAVDESS-dataset. For this dataset, 24 professional actors have been recorded, and they played the emotion based on the given label. In opposition, the participants for the ETH dataset labeled an emotion that occurred by external stimuli based on their understanding. Another difference was that the labels consisted of discrete emotions, rather than the valence and arousal space. For the pipeline with the RAVDESS-dataset, we used all eight given labels, and the accuracy was around 0.95. With this result, we were sure that the overall pipeline is working and that we are extracting useful features. For the ETH-dataset, the specified limitations are probably leading to lower accuracy.
Facial Restoration
Solving exercises at home on a tablet limits the software to rely on the built-in camera, which is most likely filming the ceiling for most of the time. With a small attached mirror on the tablet and our video restoration pipeline to reconstruct the face, we improved the facial recognition to be valid almost always. Without these adjustments, only a few sequences would have been useful from the front camera.
We introduced and implemented the following steps for the facial restoration pipeline with Python and OpenCV:
- Mirror Handling: Convert the raw input of the video source to have a consistent orientation of the face.
- Face Detection: With some parts of the face occluded in the video after the first step, many face detection algorithms had problems to detect the face at all. In this step, the face is inpainted with the most recent information, and the face detection was run after this. As a result, double as many frames became valid, which could be used for the feature extraction.
- Face Restoration: In this step, the face is restored based on the information of the previous face detection.
- We used a generative neuronal network (inpainting-model).
- We trained the inpainting-model on the CelebA-HQ dataset with the expected occlusions.
- Based on the face detection, the correct input was generated for the inpainting-model, and the output could be used to restore the frame.
With this restoration pipeline, we restored all front-camera videos for each participant and applied the same machine learning pipeline as for the GoPro videos. These models performed remarkably similar, which means that for further experiments, only the tablet can be used without an external video source.
My finished tasks (Summary)
Emotion Prediction
- Analysis of a big dataset:
- Protocols: 29.9 GB
- Video files: 1.44 TB
- Extracted features from OpenFace: 46.0 GB
- Feature extraction:
- Apply existing frameworks (Affectiva und OpenFace).
- Build a smooth feature extraction pipeline, which can be applied on many videos.
- Search and analyze existing studies/papers for useful features.
- Analyze the significance of the features.
- Machine Learning:
- Implementation of a learning pipeline which considers the window of interest.
- Cross-validation
- Hyperparameter optimization
Facial Restoration
- Restoration Pipeline:
- Implement a pipeline to edit video files easily. For each video, different steps and parameters can be defined.
- Include OpenCV functionality for single steps.
- Inpainting Model:
- Training of an existing implementation of an inpainting model based on Keras/TensorFlow. I used the dataset CelebA-HQ (30 GB) and the expected occlusions of our problem. I did the training with my notebook with an Nvidia GTX 1070 within eight days.
- Include the model in the restoration pipeline, which requires a correct extraction of the video part for the model input.

That Failed Bank Robbery
For the lecture “Game Programming Laboratory” we created a game with the theme “Alfred Escher”. In a group of five master students, we had to create the game from scratch. Within 14 weeks we needed to have a final result which we demonstrated during a public presentation live on the Xbox.
To link the game with the given theme, we decided to let two dumb robbers rob a bank. The plan of course failed and so each of the robbers needs to collect as much money as possible before the police arrive. To be faster with collecting the valuables, each robber has a street-vehicle with some specific properties. We have different modes which are spawning different valuables with different probabilities. Additionally, the game can be played alone, in a “1 vs 1” or “2 vs 2” player mode.
One of the input requirements was to use C# and MonoGame. For more information about the lecture: http://www.gtc.inf.ethz.ch/education/GameProgrammingLaboratory.html
My tasks
- Implementation and integration of physics (based on Jitter).
- Create visual effects as lens flares, wheel traces, police lights, wheel animations, particle effects, post-processing effects.
- Optimization for rendering and memory management (hardware instancing of the models so that a model is loaded once and for each instance only the new transformation matrix is sent to the GPU-Buffers).
- Git-Administrator: responsible for merges and releases.
- Publishing and testing on the Xbox.

MRI-Analysis
During the lecture “Machine Learning”, I did the three required projects. To be able to write the exam, one had to pass the public baseline for each project. Each project had to be written in a given framework in Python.
Project 1: Predict a person’s age from a brain scan. (more information: ml-project-1)
For this project, the training data consisted of 278 different brain scans and was about 8GB. The test data contained 138 brain scans.
My rank: 52/461 => top 12%
Project 2: Predict a person’s disease stage from their brain scan. (more information: ml-project-2)
For this project, the training data consisted of 278 different brain scans and was about 8GB. The test data contained 138 brain scans.
My rank: 45/381 => top 12%
Project 3: Echocardiogram classification. (more information: ml-project-3)
For this project, the training data consisted of 6821 different time-series data about the heart-frequency and was about 1GB. The test data contained 1706 records.
My rank: 23/383 => top 7%
My tasks
- Work with big datasets
- Project 1: 8 GB (278 training samples; 138 test samples; 6’443’008 features)
- Project 2: 8 GB (278 training samples; 138 test samples; 6’443’008 features)
- Project 3: 1.16 GB (6822 training samples; 1706 test samples; 18’286 features)
- Analysis of existing papers to find usable features.
- Implementing the machine learning pipeline in Python with Numpy, SkLearn, and BioSPPy.

N-Body Simulation
In the lecture “Physically Based Simulation”, we implemented a simulation for sun, planets, and asteroids. The main goal was to use many different objects, which are all influencing each other. Therefore, we needed to optimize some calculations and implement an accurate real-time collision detection.
The application is written in C++ and uses the framework OSG for rendering. Each simulation can be loaded within a JSON-file, which makes it easy to test out different start states for a simulation. For some simulations, we used a python script for calculating a stable status for a lot of objects.
This project has been awarded the 3rd place out of all other student projects (about 20).
More information about the lecture and the other winning projects (Hall of Fame – 2017): https://graphics.ethz.ch/teaching/simulation17/home.php
My tasks
- Setting up the application with CMake: C/C++, OpenSceneGraph, CGAL, Eigen, Boost
- Set up the underlying framework code.
- Implementation of visual effects: stardust, bump-map, shadow, shaders.
- Collision-Detection:
- Broad-Phase: Sweep and Prune implementation
- Narrow-Phase: Gilbert-Johnson-Keerthi Algorithm for detecting a collision, Expanding-Polytope Algorithm for calculating the collision details
- Extremely basic game-play to fly with the Star Fighter through an asteroid-field.

Shape Modelling and Geometry Processing
For the lecture “Shape Modelling and Geometry Processing”, I implemented algorithms for different problems. For the given tasks, the framework libIGL must be used, which is written in C/C++ and uses Eigen.
My tasks
- SQRT 3 Subdivision: remeshing a model. (Read the paper)
- Implicit Surface Reconstruction: reconstruct a model given by measured data-points.
- Mesh Parametrization: Map a texture from the 2D to the 3D space.
- Shape Deformation: Calculate the deformation of a model by only transform some helping handles.
- Geodesic Heat/Distance: Implementation of the paper A New Approach to Computing Distance Based on Heat Flow

Raytracer
For the lecture “Computer Graphics” my task was to implement a ray-tracer. The basic framework to start with was Nori. During the semester we added basic functionality like light, different surfaces and materials. At the end, we had to implement additional self-defined features and render a picture to a given theme: Once upon a time.
For the final picture I rendered a fairy tale billiard in which each different pair of balls are representing a different fairy tale.
The ray-tracer currently contains following features:
- Integrators
- Average Visibility Integrator
- Direct Illumination Integrator
- Path Tracing
- Light Sampling
- Spotlight
- Shape Area Light
- Photon Mapping
- Multiple Importance Sampling
- Environment Map Emitter
- Materials
- BRDF Sampling
- Dielectric BSDF
- Texture (images, mirror, bump maps, MIP map)
- Motion Blur

Computer Vision Projects
For the lecture “Computer Vision”, I had to solve each week a new task to hand in. All the tasks had to be solved with Matlab, and a report had to be written with the conclusion about the implementation, advantages, disadvantages, and problem cases of the implemented algorithms.
My tasks
- Create a feature detector/descriptor to find matching features between two images. The first task was to implement the Harris corner detector, and in a later step, SIFT features had to be extracted.
- Implementation of the “Direct Linear Transform algorithm” and the “Gold Standard algorithm” to calibrate the camera with intrinsic parameters and to estimate the distortion coefficients of the lens. As we have then the relative position of the camera, we can render objects with the correct transformation on the picture.
- Implementation of the “Monte Carlo Localization using Particle Filter” to help a robot to localize himself in a 2D corridor.
- Estimation of the Fundamental Matrix, Essential Matrix, and Camera Matrix with the help of the RANSAC.
- Reconstruction of a 3D object from multiple calibrated images with a naive silhouette extraction algorithm.
- Image segmentation with the “Mean-Shift Segmentation” and the “EM Segmentation” (Expectation-Maximization).
- Triangulation based on multiple images from an object with different angles to create the structure/model.
- Building a condensation tracker which is based on color histograms. This was applied to various videos with different objects, from which one has been tracked.
- Image Categorization with a bag-of-words image representation.

Algorithms and Data Structures
For the lecture “Algorithms and Data Structures”, I programmed a few learned things with C++. For representation on the Windows App, I used XAML. For most of the examples, default values are generated and inserted to imediately see a possible result.
- Trees
- Natural Binary Tree
- Even Counting Tree
- AVL Tree (Adelson-Velskii and Landis)
- Splay Tree
- Max Heap Tree
- Min Heap Tree
- Fibonacci Heap Tree
- Greedy
- Lists
- Linear List
- Double Linked List
- Move To Front List
- Stack (LIFO)
- Queue (FIFO)
- Hashing
- Dynamic Programming
- Mars Mission (2D tile path finding with highest value)
- Longes Common Subsequence
- Longest Ascending Subsequence
- Knapsack
- Branch and Bound
- Knapsack
- Scanline
- Non Dominated Points
- Convex Hull
- Segment Intersection
My tasks
- Implementation of the algorithms and data structures in C++ and Xaml in Visual Studio.

My-BKW: Customer Portal
The customer portal (https://my.bkw.ch) allows the customer to see the invoices (current or archived), analyze the efficiency, and start various processes (moving, product change, etc.).
I realized this project with two coworkers. In the beginning, we implemented everything with Angular JS. Later, we upgraded the project to run on Angular 4 so that we could use the framework from BKW. The portal is receiving and storing the data to the SAP system via REST-services and uses Keycloak as an authentication method.
More information about the project: https://inpeek.ch/projekte/mybkw/
My tasks
- Project planning in SCRUM.
- Requirement engineering, conception, modeling, testing, and development of web applications in JavaScript.
- Implementation in Angular 4 with WebStorm.
- Device- and browser-independent implementation.

Website: www.monis-shop.ch
For my mother I built this website with PHP and symfony. For this website I’m responsible since 2014.
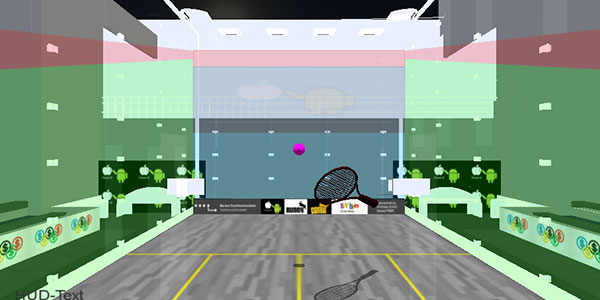
3D-Squash im C.A.V.E.
The goal for the Bachelor-Thesis was to create a Squash game in the CAVE (Computer Automated Virtual Environment). The game is projected onto four of the six sides in the room, and the racket can be controlled with a haptic device, the Phantom Sensable Omni. The walls and projectors were polarized to generate the 3D effect two project two pictures and to enhance the immersion into the virtual reality.
A classmate and I did the thesis together, splitting up the tasks equivalently so that both of us worked in every area we had to implement something.
We had to use the framework from the school, the I3D, which is written in C/C++ and built on:
- OpenSceneGraph: Rendering and scene-handling
- Bullet: Physics
- Equalizer: Communication between all systems (overall about 11 computers are used which all need to be synced)
- Chai3D: Handling of the haptic devices
Documents (German)
My tasks
- Modeling of the scene.
- Dynamic scene generation based on a file.
- Physics integration: Simulation and collision detection.
- Haptic integration: fixed limitation that only one input device could be used (driver bug).
- Applying the squash rules for the game flow.
- Implementing the visual effects (water in the main-menu, textures, etc.).

Partner Portal (QMC)
Implementation of the portal (https://qmc.quickline.ch) for the Quickline partners, where they could manage their customers, products, etc.
The portal was implemented with C#, MVC and Bootstrap in Visual Studio. Additionally, we set up an automatic build system with the TFS, which deploys the commits automatically on a test system, but only if all unit-tests are run correctly. The data was stored in a MS-SQL database, which historically used many database triggers and procedures. Many of those we replaced during the redesign in business classes in C# to have a better maintainability.
My tasks
- Develop software application with Visual Studio 2013, Team Foundation Server 2013, SQL-Management Studio
- Redesign the portal from vb.NET to C# with the technologies: ASP.NET MVC, Web Api, WCF, SQL-Server
- Responsible for part of the application
- Collecting requirements from coworker within other departments
- Planning the project within the release cycle of the overall application
- Collaboration within the SCRUM team
- Help shaping the software quality (Code-Reviews, unit tests, deployment process)
- Knowledge transfer to the DevOps-team and hotfixing

Multiplayer PacMan
During the lecture “7301p Projektarbeit 1” I redesigned the Pacman with a classmate as a multiplayer game. The challenge was to find a good multiplayer-mode which suits the game as well to implement it to be playable in the local network.
We decided to have a pacman for each player, playing against each other and having the ghosts as common enemy. Each ghost randomly select a new target-player after a given time-period. As an extra, there are some special power-ups available to make the gaming even more competing.
Documents (German)
My tasks
- Level generation based on a text-format stored in a mysql-database
- Implementation of the game
- Game-modes and game-state
- Controlling of the player
- Pathfinding for the ghosts
- Internationalization
- Dynamic menus, each defined in an XML-file
- Design of the UI
- Implementation of the network-communication
- Graphics made in Adobe Photoshop

Webshop
For the lecture “7054q Web Programming”, it was required to implement a fictive online shop. Everything needed to be implemented from with PHP, MySQL, XML, and JavaScript/JQuery. A classmate and I created an online shop for James Bond gadgets.
We structured our code to be written in a standard OOP structure. Additionally, we implemented a small database framework that allows generating the queries based on an object, which makes it easy to add new objects and using them right away.
The online shop can be used in 4 different languages, and an admin can easily manage all products and orders in a separate view. We tried to make the order process as simple as possible.
My tasks
- Implementation of the PHP-framework with following requirements:
- Easy usage of dynamic database objects.
- Automatic generated administration pages to manage defined database objects with an easy interface.
- Simply translation.
- Template independent.
- Modeling of the MySql database.
- Implementation of the order process and the product search.

Support-Portal
The portal enabled the customers to get help about their problems quickly. They could search the knowledgebase and the FAQ or could download some further software which might help them to solve the issue. The support-employees could manage all these articles in CRM in different languages.
If no help was found yet, a new incident could be opened quickly on the website, which created an incident directly in MS CRM. The support-employees could then edit the incident and reply with a comment. Once a reply is made, the customer received an email-notification and could log in back with the incident number and email address. Either a new message could be written, or the incident could be closed. The complete communication was always available for both the customer and the support-employees.
Additionally, I wrote a small windows application for the support-employee, which showed them all the needed information to keep organized. Further, I created a small admin-website, which showed some critical statistics about the open (and closed) incidents, which allowed to balance the workload of each employee as well as keep track of all incidents. The last website was shown on a screen in the office.
My tasks
- Realizing software applications with Visual Studio 2010 and ASP.NET, MS CRM, SQL-Server, and Web Services.
- Web portals for customers and business partners.
- Implementing and testing customizations and extensions for MS CRM.
- Software tools for the support-coworker for better control of the incidents.
- Realization of the company websites with Typo3.

CRM Customizations
MS CRM was the central system which contained all information about the customers, marketing activities, support and so on. I customized and extended it on a regular basis for the current needs of the company and employees. For this, I wrote many plugins to make the processes more efficient and customized/created entities to contain all the needed data. Additionally I created many applications (web-based or desktop-applications) which used CRM to read from and store data to.
My tasks
- Realizing software applications with Visual Studio 2010 and ASP.NET, MS CRM, SQL-Server, and Web Services.
- Web portals for customers and business partners.
- Implementing and testing customizations and extensions for MS CRM.
- Software tools for the support-coworker for better control of the incidents.
- Realization of the company websites with Typo3.

Websites (Typo3)
I realized many websites from the apprenticeship until the late 2018. All these websites are done with Typo3, TemplaVoila and sometimes self-written extensions in PHP.
- http://www.neumatt-fitness.ch (2003 – 2014)
Website for the gym-center “Neumatt Fitness” in Gerlafingen. - http://www.diraekt-vo-stubers.ch (2005 – 2018)
Website for a farm with a shop in Biberist. The order forms were written in PHP with an easy admin tool behind. - http://www.villa-sanluca.ch (2006 – 2018)
Website for a Bed & Breakfast in Nyon. - http://www.physio-jost.ch (2010 – 2014)
Website for a physiotherapy studio in Gerlafingen. - http://www.x-tec.ch (2010 – 2016)
Website for a small sound technique renting company in Gerlafingen. - http://www.hilarion-gmbh.ch (2012 – 2018)
Website for my father’s office in Solothurn.

The Cloning-Elephant-Hunt
This game was my first 3D game, which reminds strongly at the Moorhuhn game. I realized the game with the help of the book for programming with “3D Game Studio 5”. I did all the models, textures, and animations by my self with the tools from the “3D Game Studio 5” and Photoshop.
Game idea
You have to fight against elephants which can clone themselves. Additionally, new elephants can jump out of the airplanes which are flying above your head. All this has to be prevented as fast as possible, and all the elephants need to be eliminated. You receive munition and rockets on the go by the friendly helper. The game is won, if all elephants are disposed of within a given time.
Gaming concept
You find yourself on a vast lawn, surrounded by many elephants. The controlling is done completely with the mouse as you can’t move but only turn around. All crucial information is shown at all times on the display (number of shoots, number of elephants, etc.).
My tasks
- Creating the models, textures, and animations for the elephants, activists, airplanes, trees
- Level design for winter and summer
- Programming with the programming language of “3D Game Studio 5” which is based on C.
- 2D graphics with Photoshop